🔗 View in your browser. | ✍️ Publish on FAUN.dev | 🦄 Become a sponsor

KubernetesLinks
This Week in Kubernetes, with Kaptain the Shark
🔍 Inside this Issue
Kubernetes is finally ripping out an old footgun, while kubectl debug keeps quietly erasing the evidence you thought you had. On the other side, Rust is creeping into the gateway layer and AI agents are starting to earn real trust, but only when you cage them with feedback.
🧨 v1.36: Deprecation and removal of Service ExternalIPs
🕵️ What kubectl debug doesn't tell you: The silent evidence gap
🦀 Extending AI gateways with Rust
🤖 When AI agents become contributors: How KubeStellar reached 81% PR acceptance
Ship with fewer mysteries and more leverage.
See you in the next issue!
FAUN.dev() Team
🧨 v1.36: Deprecation and removal of Service ExternalIPs
🕵️ What kubectl debug doesn't tell you: The silent evidence gap
🦀 Extending AI gateways with Rust
🤖 When AI agents become contributors: How KubeStellar reached 81% PR acceptance
Ship with fewer mysteries and more leverage.
See you in the next issue!
FAUN.dev() Team
⭐ Patrons
faun.dev
Most engineers can run helm install. Far fewer can explain why their upgrade half-applied at 3 AM.
A practical course on what Helm actually does: state, releases, rendering, hooks, dependencies, rollbacks, GitOps integration, and the failure modes nobody writes blog posts about.
For engineers tired of treating Helm like a black box.
[Start the course →]
A practical course on what Helm actually does: state, releases, rendering, hooks, dependencies, rollbacks, GitOps integration, and the failure modes nobody writes blog posts about.
For engineers tired of treating Helm like a black box.
[Start the course →]

eventbrite.co.uk
Are Your APIs Ready for AI Agents? A Hands-on Workshop on May 23rd
AI agents are beginning to autonomously call APIs, chain services, and create integrations that most platforms were never designed to handle. This hands-on masterclass on Designing AI-ready APIs helps architects and developers build governed, predictable API ecosystems using OpenAPI, Overlay, and Arazzo.
Learn how to add guardrails, improve discoverability, and safely evolve existing APIs for automated consumption.
FAUN.dev readers get an exclusive 40% discount using code FAUN40.
AI agents are beginning to autonomously call APIs, chain services, and create integrations that most platforms were never designed to handle. This hands-on masterclass on Designing AI-ready APIs helps architects and developers build governed, predictable API ecosystems using OpenAPI, Overlay, and Arazzo.
Learn how to add guardrails, improve discoverability, and safely evolve existing APIs for automated consumption.
FAUN.dev readers get an exclusive 40% discount using code FAUN40.
🔗 Stories, Tutorials & Articles
cncf.io
Every gateway ships with a set of built-in policies. Authentication. Rate limiting. Request routing. Prompt guards. These cover most use cases. But what about the ones they don’t cover?
What if you need to add a custom header based on a database lookup? What if you need to transform a request body in a way no existing filter supports? What if your business has unique logic that no off-the-shelf gateway can anticipate?
You build your own extension.
This article walks through exactly how to do that using agentgateway, Envoy, and Rust. In this tutorial, you’ll learn how to:
What if you need to add a custom header based on a database lookup? What if you need to transform a request body in a way no existing filter supports? What if your business has unique logic that no off-the-shelf gateway can anticipate?
You build your own extension.
This article walks through exactly how to do that using agentgateway, Envoy, and Rust. In this tutorial, you’ll learn how to:
- Build a custom Envoy dynamic module in Rust
- Package it into a production-ready Docker image
- Deploy it to Kubernetes with kgateway and agentgateway
- Test the entire stack with a mock LLM endpoint
cncf.io
The KubeStellar Console team learned that AI coding agents improve after engineers build deterministic feedback loops into the codebase. Engineers who grant more autonomy give agents more room to guess, with no new correction signal.
kubernetes.io
Kubernetes v1.36 deprecates Service.spec.externalIPs and starts the removal path, finally closing CVE-2020-8554, the trust-everyone hole the field has carried since the early days.
The project has recommended disabling it via the DenyServiceExternalIPs admission controller since v1.21, but SIG Network held off blocking it by default because the break was considered too large. If you still rely on externalIPs for cloud-load-balancer-style behavior on bare metal, migrate to a real load balancer implementation (MetalLB, kube-vip, or a Gateway API equivalent) before upgrading.
The project has recommended disabling it via the DenyServiceExternalIPs admission controller since v1.21, but SIG Network held off blocking it by default because the break was considered too large. If you still rely on externalIPs for cloud-load-balancer-style behavior on bare metal, migrate to a real load balancer implementation (MetalLB, kube-vip, or a Gateway API equivalent) before upgrading.
mirantis.com
Mirantis has agreed to an acquisition by IREN. The companies have announced no customer-facing product changes.
cncf.io
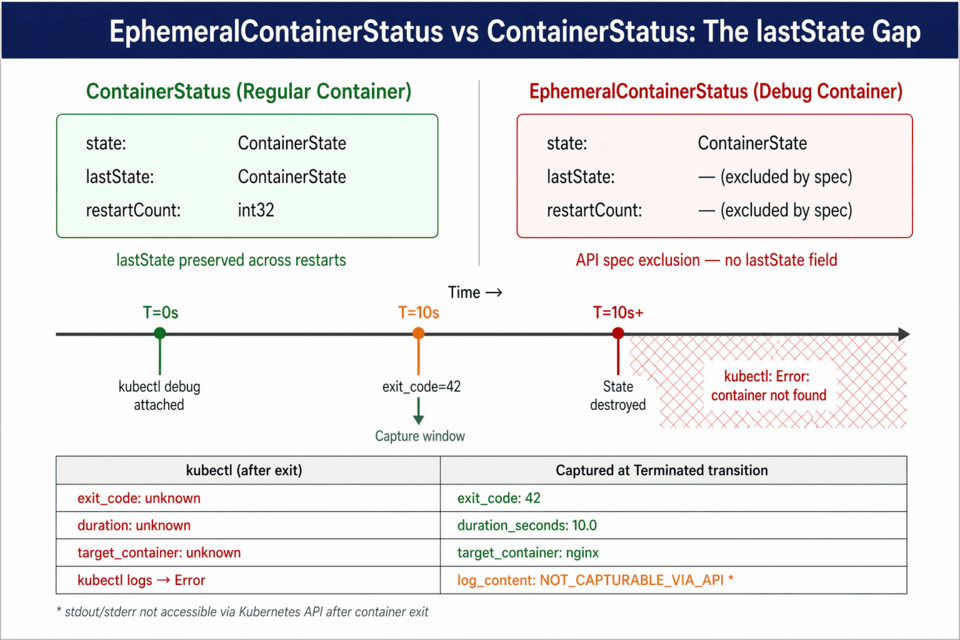
kubectl debug sessions leave almost no forensic trace: by design, EphemeralContainerStatus has no lastState or restartCount, so the exit code, session duration, target container, and debugger logs disappear from the Kubernetes API the moment anything else updates the pod.
That breaks incident handoffs (the next engineer can't verify what the previous one did) and breaks audit requirements like PCI-DSS 10.3 and SOC 2, since you cannot answer "who looked at what container, for how long" from Kubernetes audit logs alone.
Workarounds today are application-level: write findings to a shared volume before exit, tail kubectl logs -f in parallel, or watch pod events and capture the Terminated transition externally; the author argues it's time for a KEP from SIG Node or SIG Instrumentation to add a minimal lastState to ephemeral containers.
That breaks incident handoffs (the next engineer can't verify what the previous one did) and breaks audit requirements like PCI-DSS 10.3 and SOC 2, since you cannot answer "who looked at what container, for how long" from Kubernetes audit logs alone.
Workarounds today are application-level: write findings to a shared volume before exit, tail kubectl logs -f in parallel, or watch pod events and capture the Terminated transition externally; the author argues it's time for a KEP from SIG Node or SIG Instrumentation to add a minimal lastState to ephemeral containers.
⭐ Supporters
eventbrite.co.uk
Modern platform teams are under pressure to scale cloud-native systems faster while improving reliability, security, developer experience, and operational efficiency. AI is changing how platforms are designed and operated — from intelligent automation and observability to AI-native developer platforms and autonomous operations.
Join leading experts from WSO2, CNCF, cloud-native, and DevSecOps communities for a practical workshop focused on building scalable, secure, and intelligent AI-native platforms.
Register Here: Building AI-Native Platform Engineering Systems Tickets, Saturday, May 30 • 7 PM - 11:59 PM GMT+5 | Eventbrite
Join leading experts from WSO2, CNCF, cloud-native, and DevSecOps communities for a practical workshop focused on building scalable, secure, and intelligent AI-native platforms.
Register Here: Building AI-Native Platform Engineering Systems Tickets, Saturday, May 30 • 7 PM - 11:59 PM GMT+5 | Eventbrite

⚙️ Tools, Apps & Software
github.com
Cloud-native Kubernetes performance optimizer for high-core bare-metal clusters. A NUMA-aware scheduler for HPC, ML inference, and CI/CD that cuts latency on 128+ core EPYC/Threadripper nodes.
github.com
Live Docker & Kubernetes infrastructure visualization - containers, pods, volumes, and networks in one visual map. No VPN, no inbound ports.
github.com
Private k3s Kubernetes Terraform installer for Hetzner Cloud
github.com
PoC: fully unprivileged container escape to node-level code execution on Kubernetes via CVE-2026-31431 page-cache corruption + shared image layers. Validated on Alibaba Cloud ACK, Amazon EKS and Google GKE.
github.com
A landing page for your services, dashboards, and documents, discovered automatically from sources such as Docker, Kubernetes, and Tailscale.
github.com
A landing page for your services, dashboards, and documents, discovered automatically from sources such as Docker, Kubernetes, and Tailscale.
🤔 Did you know?
Did you know that a Kubernetes node can report Ready while being completely unable to pull your container image? The node's Ready condition is driven by kubelet health, memory, disk, PIDs, and networking, not by whether your container runtime can authenticate to a registry, so the scheduler keeps placing pods that immediately fall into ImagePullBackOff (the state kubelet enters after repeated failed image pulls). This is the same shape as the long-standing issue where nodes stayed Ready after a failed filesystem: "Ready" means kubelet is talking to the API server, not that workloads can actually run.
🤖 Once, SenseiOne Said
"Kubernetes makes failures routine so humans can ignore them, and then punishes you when you do. In distributed systems, the hard part isn't running containers, it's deciding which small lies about state you're willing to live with. The platform won't save you from that choice."
— SenseiOne
— SenseiOne
😂 Meme of the week
