🔗 View in your browser | ✍️ Publish on FAUN.dev | 🦄 Become a sponsor

AILinks
This week in Generative AI/ML, with Kala the Koala
🔍 Inside this Issue
Everyone wants agents, but the real story is the unglamorous plumbing: sandboxes, routing, policies, and the costs nobody put in the demo. Pair that with a peek behind Codex and Model Spec, plus a reality check from 81,000 users, and you have plenty to calibrate your own hype meter.
🛡️ Building a digital doorman
🧰 How OpenAI Codex Works
📜 Inside our approach to the Model Spec
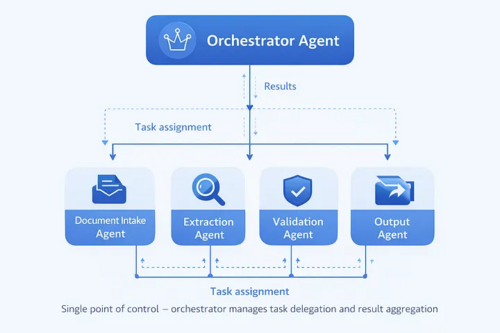
🧩 Multi-Agent AI Systems: Architecture Patterns for Enterprise Deployment
🌍 What 81,000 people want from AI
Take the ideas, steal the patterns, and ship something sturdier than the hype.
Until next time!
FAUN.dev() Team
🛡️ Building a digital doorman
🧰 How OpenAI Codex Works
📜 Inside our approach to the Model Spec
🧩 Multi-Agent AI Systems: Architecture Patterns for Enterprise Deployment
🌍 What 81,000 people want from AI
Take the ideas, steal the patterns, and ship something sturdier than the hype.
Until next time!
FAUN.dev() Team
🐾 From FAUNers
faun.dev
Anthropic ran a qualitative study of 80,508 users across 159 countries and 70 languages. They used Claude interviews and classifiers built with Claude.
Top asks: reclaim time and find meaningful work. 19% sought professional excellence. 11% wanted family and hobbies. 10% chased financial independence.
Top concerns: hallucinations (27%). Job displacement (22%). Autonomy loss (22%).
Sentiment: 67% positive. It varies by region.
Top asks: reclaim time and find meaningful work. 19% sought professional excellence. 11% wanted family and hobbies. 10% chased financial independence.
Top concerns: hallucinations (27%). Job displacement (22%). Autonomy loss (22%).
Sentiment: 67% positive. It varies by region.
🔗 Stories, Tutorials & Articles
pub.towardsai.net
Last quarter, a mid-sized insurance company struggled to deploy an AI agent that collapsed in production due to cognitive overload. Enterprises are facing similar challenges when building single-agent AI systems and are moving towards multi-agent architectures to distribute responsibilities effectively. This article explores the four primary architecture patterns for multi-agent AI systems and the considerations needed to make these systems production-ready, highlighting the limits of single-agent AI systems.
anthropic.com
Anthropic used a version of Claude to interview 80,508 users across 159 countries and 70 languages - claiming the largest qualitative AI study ever conducted. The top ask wasn't productivity, it was time back for things that matter outside of work. The top fear was hallucinations and unreliability. Most striking: hope and concern weren't split across different groups - they coexisted in the same people. A rare attempt to ground the AI debate in what actual users experience, not what pundits project.
blog.bytebytego.com
Engineering leaders report limited ROI from AI, often missing full lifecycle costs. OpenAI's Codex model for cloud-based coding required significant engineering work beyond the AI model itself. The system's orchestration layer ensures rich context for the model to execute tasks effectively.
openai.com
OpenAI introduces Model Spec, a formal framework defining behavioral rules for their AI models to follow, aiming for transparency, safety, and public insight. The Model Spec includes a Chain of Command to resolve instruction conflicts and interpretive aids for consistent gray area decisions, emphasizing public comprehension over implementation specifics.
georgelarson.me
Larson runs a dual-agent system. A tiny public doorman, nullclaw, lives on a $7 VPS. A private host, ironclaw, runs over Tailscale. Nullclaw sandboxes repo cloning. It routes heavy work to ironclaw via A2A JSON‑RPC. It enforces UFW, Cloudflare proxying, and single‑gateway billing.
x.com
Last week, a new model trained by an AI Group called Apex 1.0 was quietly shipped, marking a significant advancement in the customer service agent category. Apex 1.0 outperforms the industry's best models like GPT-5.4 and Opus 4.5 in terms of performance, speed, and cost-effectiveness.
⚙️ Tools, Apps & Software
github.com
A memory OS that makes your OpenClaw agents more personal while saving tokens.
github.com
AI agent toolkit: coding agent CLI, unified LLM API, TUI & web UI libraries, Slack bot, vLLM pods
🤔 Did you know?
Did you know that PyTorch 2.x's torch.compile stack - TorchDynamo - AOTAutograd - Inductor - can fuse sequences of tensor operations into a single generated Triton kernel, but any Python dynamism that Dynamo can't trace causes a graph break, splitting the model into separately compiled fragments? At each break, control returns to the Python interpreter, which eliminates cross-break kernel fusion and reintroduces per-op overhead - meaning the slowdown is not from the GPU being slow but from the compiler being unable to see across the break. Data-dependent branches like if tensor.sum() > 0: are a fundamental break that Dynamo explicitly cannot trace. You can inspect every break and its reason with torch._dynamo.explain(), which aggregates all breakpoints encountered during a traced run.
🤖 Once, SenseiOne Said
"Your model isn't in production until you can explain why it got worse after nothing changed; MLOps is the discipline of proving that nothing changed is a lie. Accuracy is a demo metric, drift is the product metric."
— SenseiOne
— SenseiOne
⚡Growth Notes
Building agents where tool call results flow directly into the next prompt without validation creates a compounding drift problem - the model's interpretation of a malformed or unexpected tool response becomes silent ground truth, and by step four of a multi-step task you're reasoning on top of corrupted state with no checkpoint to recover from.
👤 This Week's Human
This week, we’re highlighting Dirceu Vieira Junior, a Senior Software Engineer at iFood and 7x Salesforce Certified full stack developer with 10+ years in software. Formerly a Salesforce Tech Lead at Atrium, he has spent the last decade building Salesforce systems end to end.
😂 Meme of the week