🔗 View in your browser. | ✍️ Publish on FAUN.dev | 🦄 Become a sponsor

DevOpsLinks
#DevOps #SRE #PlatformEngineering
📝 The Opening Call
Hey there,
Starting today, in every issue, you’ll now find a short career insight built for engineers who want to grow with intention.
These notes blend long-term strategy with specific technical habits, focusing on leverage, timing, and smart positioning. The tone is direct, the kind of guidance a senior engineer would share when they genuinely want someone to move up.
Here is our methodology, or at least what we try to achieve:
We build each note by pulling ideas from well-known books on personal development, career growth, and long-term decision making. Then we translate those ideas into the technical world: the world of systems, codebases, architectures, and real engineering constraints.
The goal, as you can guess, is to turn broad principles into something a developer can actually use in their daily work.
You can find this new section "Growth Notes" at the end of each issue!
We hope you like it! You feedback is welcome!
Starting today, in every issue, you’ll now find a short career insight built for engineers who want to grow with intention.
These notes blend long-term strategy with specific technical habits, focusing on leverage, timing, and smart positioning. The tone is direct, the kind of guidance a senior engineer would share when they genuinely want someone to move up.
Here is our methodology, or at least what we try to achieve:
We build each note by pulling ideas from well-known books on personal development, career growth, and long-term decision making. Then we translate those ideas into the technical world: the world of systems, codebases, architectures, and real engineering constraints.
The goal, as you can guess, is to turn broad principles into something a developer can actually use in their daily work.
You can find this new section "Growth Notes" at the end of each issue!
We hope you like it! You feedback is welcome!

🔍 Inside this Issue
One tiny permissions tweak cratered Cloudflare, while another team walked off AWS and shaved $1.2M, this week is about taking back control. Post‑quantum signing, EKS network maps, caching that won’t betray you, S3 cost math, and a faster Valkey, open a few tabs and come away dangerous in the best way.
🧠 A complete guide to HTTP caching
🛠️ AWS to Bare Metal Two Years Later: Answering Your Toughest Questions About Leaving AWS
🔥 Inside Cloudflare's Worst Outage Since 2019: How a Single Config File Broke the Internet
📊 Grafana 12.3 Lands With New Learning Tools, Better Logs, and a Critical Security Fix
🌐 Monitor network performance and traffic across your EKS clusters with Container Network Observability
🔐 Post-quantum (ML-DSA) code signing with AWS Private CA and AWS KMS
💸 S3 Storage Classes: Fast Access
🧩 Terraform Stacks: A Deep-Dive for Azure Practitioners in Europe
⚡ Valkey 9.0 Released: Faster Clusters, New TTL Controls, and Big Networking Gains
🛡️ WTF is ... - AI-Native SAST?
Smarter choices, fewer incidents—make the next commit count.
Have a great week!
FAUN.dev() Team
🧠 A complete guide to HTTP caching
🛠️ AWS to Bare Metal Two Years Later: Answering Your Toughest Questions About Leaving AWS
🔥 Inside Cloudflare's Worst Outage Since 2019: How a Single Config File Broke the Internet
📊 Grafana 12.3 Lands With New Learning Tools, Better Logs, and a Critical Security Fix
🌐 Monitor network performance and traffic across your EKS clusters with Container Network Observability
🔐 Post-quantum (ML-DSA) code signing with AWS Private CA and AWS KMS
💸 S3 Storage Classes: Fast Access
🧩 Terraform Stacks: A Deep-Dive for Azure Practitioners in Europe
⚡ Valkey 9.0 Released: Faster Clusters, New TTL Controls, and Big Networking Gains
🛡️ WTF is ... - AI-Native SAST?
Smarter choices, fewer incidents—make the next commit count.
Have a great week!
FAUN.dev() Team
ℹ️ News, Updates & Announcements
faun.dev
Grafana 12.3 lands with interactive tutorials baked right into the UI. Log views get color highlights. Dashboards can export straight to image.
On the security front: CVE-2025-41115 is patched.
Switch template variables make it easier to flip between data sources. Tables get a glow-up too, now tweakable with inline CSS.
On the security front: CVE-2025-41115 is patched.
Switch template variables make it easier to flip between data sources. Tables get a glow-up too, now tweakable with inline CSS.
aws.amazon.com
AWS Private CA now supports post-quantum ML-DSA X.509 certificates. That means quantum-resistant roots of trust - for code signing, mTLS, and device auth. It's wired up with AWS KMS, so you can handle signing workflows using ML-DSA keys and verify them with standard tools like OpenSSL using CMS detached signatures.
Big picture: AWS is baking post-quantum crypto straight into its PKI and signing stack. It’s not just future-proofing - they're pulling the future forward.
Big picture: AWS is baking post-quantum crypto straight into its PKI and signing stack. It’s not just future-proofing - they're pulling the future forward.
faun.dev
A ClickHouse permissions tweak on Nov 18, 2025 quietly changed how metadata queries behaved. That tiny shift? It blew up a Bot Management feature file at Cloudflare, tipping it over its 200-feature cap. Once the file overflowed, proxies started crashing. Cue a wave of 5xx errors across the CDN, Workers KV, Access, and the Cloudflare Dashboard.
What can we learn: Even small internal DB changes can trip up large-scale systems in ugly, distributed ways.
What can we learn: Even small internal DB changes can trip up large-scale systems in ugly, distributed ways.
faun.dev
Valkey 9.0 drops some serious upgrades: atomic slot migrations, hash field expiration, and numbered databases in cluster mode. That trio clears old roadblocks around scale and consistency.
Performance gets a kick, too. Pipeline memory prefetching drives throughput up by 40%. Add zero-copy responses and Multipath TCP, and latency doesn’t stand a chance.
System shift: Valkey’s not just riding Redis’s coattails anymore. It’s building out a faster, leaner in-memory system on its own terms.
Performance gets a kick, too. Pipeline memory prefetching drives throughput up by 40%. Add zero-copy responses and Multipath TCP, and latency doesn’t stand a chance.
System shift: Valkey’s not just riding Redis’s coattails anymore. It’s building out a faster, leaner in-memory system on its own terms.
aws.amazon.com
Amazon EKS just leveled up with Container Network Observability - no extra tools needed. It now ships with service maps, flow tables, and performance metrics, all lit up by CloudWatch Network Flow Monitor.
You get pod- and node-level network telemetry out of the box. Zoom in on service-to-service links. Sift through high-traffic flows across internal, AWS, and external endpoints.
You get pod- and node-level network telemetry out of the box. Zoom in on service-to-service links. Sift through high-traffic flows across internal, AWS, and external endpoints.
🐾 From FAUNers
faun.pub
Unified observability provides a consistent view of distributed systems by combining telemetry data from applications, infrastructure, and services. Open standards like OpenTelemetry and distributed tracing help collect and correlate this data across different components. The integration of OpenTelemetry and distributed tracing in AWS, along with tools like AWS X-Ray, allows for better visibility and troubleshooting in complex cloud-native environments.
🔗 Stories, Tutorials & Articles
mattias.engineer
Terraform Stacks just hit GA on HCP Terraform, and they bring some real structure to the chaos. Think modular, declarative, and way less workspace spaghetti. Build reusable components (a.k.a. modules), bundle them into deployments, and wire up stacks using publish/consume patterns - complete with automated triggers downstream.
EU regions? Covered. Stack support is live there too, with full parity.
EU regions? Covered. Stack support is live there too, with full parity.
platformengineering.org
A new platform stack - Port** + GitHub Actions + HCP Terraform - is turning LLM deployment into a clean self-service flow. The result => predictable, governed pipelines that ship faster.
Infra gets standardized. Provisioning? Handled through GitHub Actions. Policies? Baked in via HCP Terraform. Port ties it all together with opinionated blueprints that hide the messy bits.
The shift: LLM ops moves from hand-rolled chaos to reusable platform rails. Enterprises get scale. Devs get speed. Everyone stops begging the infra team.
Infra gets standardized. Provisioning? Handled through GitHub Actions. Policies? Baked in via HCP Terraform. Port ties it all together with opinionated blueprints that hide the messy bits.
The shift: LLM ops moves from hand-rolled chaos to reusable platform rails. Enterprises get scale. Devs get speed. Everyone stops begging the infra team.
parsiya.net
AI-native SAST is replacing the “LLM as magic scanner” myth. Instead, the smart play is combining language models with real static analysis. That’s how teams are catching the gnarlier stuff - like business logic bugs - that usually slip through.
The trick? Use static analysis to grab clean, relevant chunks of code, then rope in RAG and purpose-built prompts to guide the LLM. Think triage, not tarot reading.
The trick? Use static analysis to grab clean, relevant chunks of code, then rope in RAG and purpose-built prompts to guide the LLM. Think triage, not tarot reading.
jonoalderson.com
A fresh guide reframes HTTP caching as less of a tweak, more of an architectural move. It breaks caching into layers - browser memory, CDNs, reverse proxies, app stores - and shows how each one plays a part (or gets in the way).
It gets granular with headers like Cache-Control, ETag, and Vary, calling out common faceplants like no-store abuse or using Vary: Cookie like it's harmless. Hint: it’s not. When cache layers slip out of sync, stale content isn't just annoying - it can quietly break critical flows.
It gets granular with headers like Cache-Control, ETag, and Vary, calling out common faceplants like no-store abuse or using Vary: Cookie like it's harmless. Hint: it’s not. When cache layers slip out of sync, stale content isn't just annoying - it can quietly break critical flows.
malithr.com
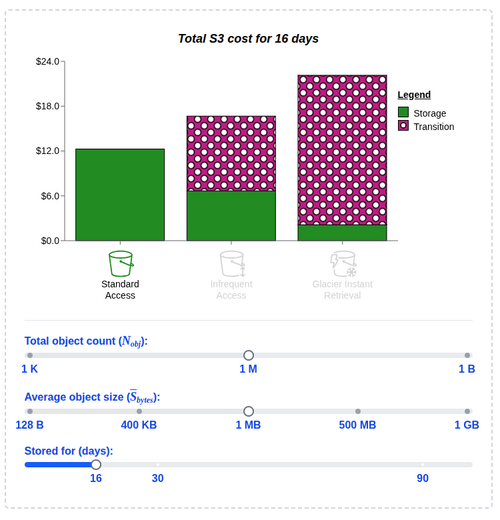
A cost deep-dive breaks down three AWS S3 storage classes - Standard, Standard-IA, and Glacier Instant Retrieval - with sharp, interactive visualizations. It maps out the tradeoffs: storage cost, access frequency, and early deletion pain.
Key tipping points surface:
- Use Standard-IA if you read the object once a month or less.
- Glacier Instant Retrieval makes sense closer to once a quarter - assuming access patterns and object sizes don’t vary much.
Bigger picture: Picking a storage class isn’t guesswork anymore. You’ve got to model it. AWS S3’s now grown a real optimization layer.
Key tipping points surface:
- Use Standard-IA if you read the object once a month or less.
- Glacier Instant Retrieval makes sense closer to once a quarter - assuming access patterns and object sizes don’t vary much.
Bigger picture: Picking a storage class isn’t guesswork anymore. You’ve got to model it. AWS S3’s now grown a real optimization layer.
oneuptime.com
OneUptime ditched the cloud bill and rolled their own dual-site setup. Think bare metal, orchestrated with MicroK8s, booted by Tinkerbell, patched together with Ceph, Flux, and Terraform. Result? 99.993% uptime and $1.2M/year saved - 76% cheaper than even well-optimized AWS.
They run it all with just ~14 engineer-hours/month. Thanks, Talos. The cloud's still in play, but only where it helps: archival, CDN, and burst capacity.
They run it all with just ~14 engineer-hours/month. Thanks, Talos. The cloud's still in play, but only where it helps: archival, CDN, and burst capacity.
⚙️ Tools, Apps & Software
github.com
Optimize your infrastructure with the Actions version of Kexa's generic alerting tools. Avoid wasting money on unnecessary infrastructure, avoidable security breaches and service failures.
github.com
secureCodeBox (SCB) - continuous secure delivery out of the box
🤔 Did you know?
Did you know Meta’s open-source load balancer Katran uses the Linux XDP and eBPF frameworks to build its packet-forwarding layer on commodity servers? Katran runs in the kernel via XDP, allowing it to scale packet processing linearly with the number of NIC Rx queues and colocate with backend services for improved density and performance.
😂 Meme of the week
🤖 Once, SenseiOne Said
"Autoscaling handles demand, not defects; in the cloud, you can multiply a bad release at line-rate. Reliability is a product decision—set SLOs and failure budgets, or your pager will do it for you."
— SenseiOne
— SenseiOne
⚡Growth Notes
Keep a weekly toil ledger
Record every repetitive on-call task with timestamps, then spend one focused hour automating the costliest item end-to-end, shipping it behind a feature flag and wiring it into dashboards, alerts, and runbooks; each quarter, use SLO error budgets to time the rollout and show leadership the hours reclaimed and MTTR reduced. This quiet, repeatable habit turns firefighting into leverage, earns you ownership of the golden paths, and sets you up naturally for Staff SRE or platform leadership roles without drama.
Record every repetitive on-call task with timestamps, then spend one focused hour automating the costliest item end-to-end, shipping it behind a feature flag and wiring it into dashboards, alerts, and runbooks; each quarter, use SLO error budgets to time the rollout and show leadership the hours reclaimed and MTTR reduced. This quiet, repeatable habit turns firefighting into leverage, earns you ownership of the golden paths, and sets you up naturally for Staff SRE or platform leadership roles without drama.
👤 This Week's Human
This week, we’re highlighting Kathryn V., a scientist, former USPTO Examiner, founder of Vatt IP Management, and mother of seven with 25+ years turning lab insight into defensible IP. She’s examined thousands of applications at the USPTO, ranked among the Top 30 Patent Drafters and Prosecutors and a #1 LinkedIn Global Influencer in Innovation/IP Law, and now builds tools like My Startup Shield™ for pre‑pitch IP readiness and My AI Examiner™ for examiner‑style prior‑art search, while mentoring teams at ASU’s Edson E+I Institute and earning a J.D. in Patent Law at Franklin Pierce.