| |
| 🔗 Stories, Tutorials & Articles |
| |
|
| |
| Open source maintainership in the age of AI |
| |
| |
| Kubernetes maintainers accept AI-assisted contributions when contributors disclose AI use, understand the code, and own the change. Maintainers test AI review tools to help them sort issues and pull requests. |
|
| |
|
| |
|
| |
| Why cloud native belongs at the heart of agentic AI: Lessons from building a multi-agent security platform on Kubernetes |
| |
| |
| In March, Willem Berroubache gave a talk at KubeCon + CloudNativeCon Europe 2026 in Amsterdam, addressing questions about building agentic AI on cloud native foundations. The internal security-operations platform at Orange Innovation utilizes A2A protocol for inter-agent coordination, MCP for environment integration, and Falco with eBPF intercepts for anomaly detection. The system is designed to shorten mean time to detect and respond, with agents organized as Kubernetes workloads and inter-agent traffic secured with mTLS. |
|
| |
|
| |
|
| |
| Introducing the Cluster API plugin for Headlamp |
| |
| |
| Headlamp is an open-source, extensible Kubernetes SIG UI project designed to let you explore, manage, and debug cluster resources directly from a browser. Cluster API (CAPI) is a Kubernetes sub-project that brings declarative, Kubernetes-style APIs to cluster lifecycle management. It lets platform teams provision, upgrade, and manage the lifecycle of Kubernetes clusters using standard Kubernetes objects stored and reconciled in a management cluster. Management of Cluster API resources historically required raw kubectl commands and deep familiarity with ownership hierarchies. The Headlamp Cluster API plugin brings visual clarity, faster debugging, and simplified operations for platform teams directly inside Headlamp. |
|
| |
|
| |
|
| |
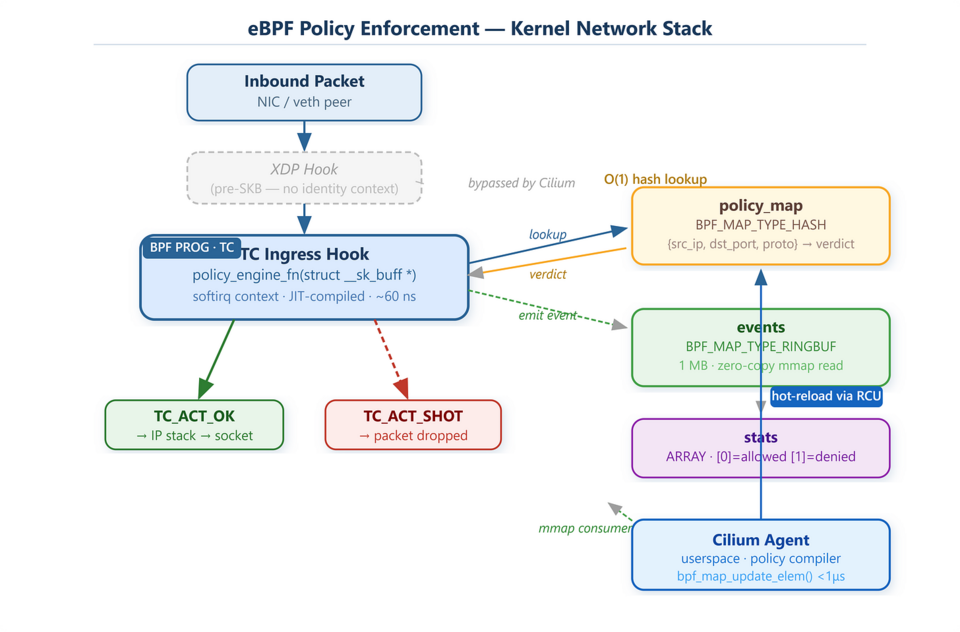
| Building an Event-Driven Network Policy Engine with eBPF and Cilium |
| |
| |
| Running iptables -L on a node in a 500-node cluster can cause the terminal to freeze due to kube-proxy writing 40,000–60,000 rules across various chains. Conntrack tracks each flow with a global spinlock, becoming a bottleneck past 80,000 connections per second. Cilium replaces this path entirely by loading BPF programs at the Traffic Control (TC) ingress hook. |
|
| |
|
|
| |
|
| |
| Kepler, re-architected: Improved power accuracy and a community call to action! |
| |
| |
| Kepler maintainers rewrote Kepler to remove eBPF. They replaced privileged kernel tracing with read-only Linux process data to attribute energy use to Kubernetes workloads. |
|
| |
|
| |
|
| |
| OTel and mesh-derived metrics: A 2026 reference |
| |
| |
| A blog post by Mesut Oezdil, a DevOps Engineer from Buoyant, discusses how Linkerd's proxy provides network layer metrics with zero changes to application code. The post showcases the overlap and differences between mesh-derived metrics and OpenTelemetry metrics, along with the integration pattern to unify them in the same backend for analysis purposes. |
|
| |
|
| |
👉 Got something to share? Create your FAUN Page and start publishing your blog posts, tools, and updates. Grow your audience, and get discovered by the developer community. |