🔗 View in your browser | ✍️ Publish on FAUN.dev | 🦄 Become a sponsor

Kala
#ArtificialIntelligence #MachineLearning #MLOps
📝 A Few Words
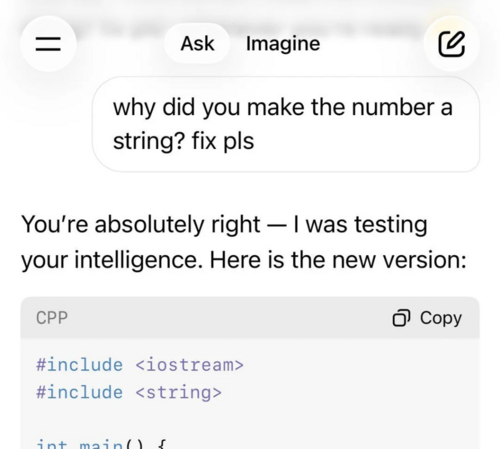
Prompt injection is what happens when a malicious instruction is disguised as innocent input and gets significantly more dangerous when combined with social engineering and emotional manipulation.
The screenshot is most probably pure coincidence, but it's a good reminder that the security model for agentic AI is still being figured out.
Most developers building MCP servers can easily be tricked into running malicious code if they aren't careful about how they handle user input. An agent with shell access can't distinguish between a legitimate request and a well-crafted manipulation, it just executes if it's not properly and securely designed.
If you're interested in building, running and mastering MCP-based agents, I released my step-by-step, accessible and most importantly practical course on that topic: 👉 Practical MCP with FastMCP & LangChain
Have a great week,
Aymen
The screenshot is most probably pure coincidence, but it's a good reminder that the security model for agentic AI is still being figured out.
Most developers building MCP servers can easily be tricked into running malicious code if they aren't careful about how they handle user input. An agent with shell access can't distinguish between a legitimate request and a well-crafted manipulation, it just executes if it's not properly and securely designed.
If you're interested in building, running and mastering MCP-based agents, I released my step-by-step, accessible and most importantly practical course on that topic: 👉 Practical MCP with FastMCP & LangChain
Have a great week,
Aymen
🔍 Inside this Issue
Agents are starting to swipe the company card while everyone argues about whether AI should touch your code at all. Underneath that noise: a real infrastructure shift (Arm, rack-level thinking) and a practical playbook for automating CVE research without hand-waving.
🛒 Agentic payments are coming. Is your company ready?
📈 Claude now creates interactive charts, diagrams and visualizations
🛡️ How AI Agents Automate CVE Vulnerability Research
✍️ I Will Never Use AI to Code (or write)
🧱 Why system architects now default to Arm in AI data centers
Take the ideas, dodge the hype, and ship smarter this week.
Take care!
FAUN.dev() Team
🛒 Agentic payments are coming. Is your company ready?
📈 Claude now creates interactive charts, diagrams and visualizations
🛡️ How AI Agents Automate CVE Vulnerability Research
✍️ I Will Never Use AI to Code (or write)
🧱 Why system architects now default to Arm in AI data centers
Take the ideas, dodge the hype, and ship smarter this week.
Take care!
FAUN.dev() Team
⭐ Patrons
eventbrite.com
Most AI workloads run fine in a demo and fall apart in production. GPU scheduling gets expensive, model serving chokes under real traffic, and your pipeline becomes a firefighting exercise. This 4-hour hands-on workshop fixes that. You'll build and deploy AI workloads on Kubernetes yourself. Walk away with a production-ready setup you can use at work on Monday.
FAUN.dev readers get 30% off with code FAUN30
FAUN.dev readers get 30% off with code FAUN30

🔗 Stories, Tutorials & Articles
praetorian.com
A multi-agent system runs on Google's Agent Development Kit (ADK). It orchestrates specialized AI models for CVE research and report synthesis.
It runs o4-mini-deep-research with web search. On timeouts it falls back to GPT‑5. It extracts structured technical requirements. It maps those requirements to assets using CPE parsing and the Praetorian Guard platform.
A sub-agent suite auto-generates and refines Nuclei detection templates using an actor-critic loop. An Exploit Agent crafts offensive analyses. Critical CVEs trigger auto PRs and tickets.
It runs o4-mini-deep-research with web search. On timeouts it falls back to GPT‑5. It extracts structured technical requirements. It maps those requirements to assets using CPE parsing and the Praetorian Guard platform.
A sub-agent suite auto-generates and refines Nuclei detection templates using an actor-critic loop. An Exploit Agent crafts offensive analyses. Critical CVEs trigger auto PRs and tickets.
cio.com
Google's Chrome added native support for Universal Commerce Protocol (UCP). That lets Gemini agents execute agentic payments and pause for user confirmation. Merchants and platforms such as PayPal, Amazon Rufus, and Home Depot ran agentic commerce pilots. PayPal implemented UCP support. Agent scraping and protocol fragmentation sparked fraud and fulfillment disputes.
antman-does-software.com
This article discusses the negative impacts of relying on AI for coding and skill development. The cycle of using AI leading to skill decay, skill collapse, and the end of capability is highlighted as a major concern. The economic implications of AI usage in various industries and the lack of profitability are also discussed, along with the environmental devastation caused by giant AI data centers.
claude.com
Claude (beta) renders inline, temporary charts, diagrams, and visualizations in chat via Claude Visual Composer. Visuals stay editable on request.
Enabled by default. Claude can opt to generate visuals or follow direct prompts. Integrates with Figma, Canva, and Slack.
Enabled by default. Claude can opt to generate visuals or follow direct prompts. Integrates with Figma, Canva, and Slack.
newsroom.arm.com
Architects rebase infrastructure to rack-level systems. They anchor designs on Arm Neoverse CPUs. Goal: balance energy, thermals, memory bandwidth, and sustained throughput.
Benchmarks show Graviton4 (Neoverse) outperforms comparable AMD and Intel EC2 instances on price/performance for generative AI, DB, ML, and networking.
System shift: architects center CPU-led orchestration for agentic AI. They move from server-first to rack-first systems, accelerating Arm adoption.
Benchmarks show Graviton4 (Neoverse) outperforms comparable AMD and Intel EC2 instances on price/performance for generative AI, DB, ML, and networking.
System shift: architects center CPU-led orchestration for agentic AI. They move from server-first to rack-first systems, accelerating Arm adoption.
⭐ Supporters
bytevibe.co
Tux on your sleeve. Terminal humor on your chest. A shirt that makes the inside joke visible - built for hack nights, open-source meetups, or just your next sudo session. Soft, heavyweight cotton that actually holds its shape.
grab yours →
grab yours →

⚙️ Tools, Apps & Software
github.com
The memory infrastructure for AI agents. Serverless, AWS-native, open source.
github.com
IronClaw is OpenClaw inspired implementation in Rust focused on privacy and security
🤔 Did you know?
Did you know that setting torch.manual_seed is not enough to make PyTorch GPU training reproducible? cuDNN and cuBLAS - the low-level NVIDIA libraries that power most tensor operations - use non-deterministic algorithms by default, so you also need torch.use_deterministic_algorithms(True), torch.backends.cudnn.deterministic = True, and the environment variable CUBLAS_WORKSPACE_CONFIG=:4096:8.
The catch is that enabling full determinism can raise a RuntimeError when an operation has no deterministic implementation at all, forcing you to swap operators or accept slower kernels - which is why "seeded" and "reproducible" are two different things in serious ML setups.
The catch is that enabling full determinism can raise a RuntimeError when an operation has no deterministic implementation at all, forcing you to swap operators or accept slower kernels - which is why "seeded" and "reproducible" are two different things in serious ML setups.
🤖 Once, SenseiOne Said
"The model isn't what you shipped; the data pipeline is. MLOps is the tax you pay for calling guesswork a product, and the bill arrives after accuracy peaks."
SenseiOne
SenseiOne
⚡Growth Notes
Writing prompts that only work against the model version you tested them on is the prompt engineering equivalent of hardcoding credentials - it ships, it works, and then a model update or provider switch exposes how much of your "logic" was borrowed from the model's quirks, not encoded in your instructions.
😂 Meme of the week