🔗 View in your browser | ✍️ Publish on FAUN.dev | 🦄 Become a sponsor

AILinks
This week in Generative AI/ML, with Kala the Koala
🔍 Inside this Issue
AI is quietly taking over the parts of engineering that produce the prettiest dashboards, while the real risk hides in the gaps nobody wrote down. The links below hit that tension from three angles: agent control planes, scaling AI help across huge codebases, and the ruthless math of token caches.
🧪 AI Is Doing the Testing Now
🕹️ Claude’s next enterprise battle is not models: it’s the agent control plane
🐳 Create Custom MCP Catalogs and Profiles
🏗️ How Code works in large codebases: Best practices and where to start
🧮 Tokenomics: the 62.5-minute rule for Claude's cache
Steal the ideas, dodge the footguns, ship with confidence.
See you in the next issue!
FAUN.dev() Team
🧪 AI Is Doing the Testing Now
🕹️ Claude’s next enterprise battle is not models: it’s the agent control plane
🐳 Create Custom MCP Catalogs and Profiles
🏗️ How Code works in large codebases: Best practices and where to start
🧮 Tokenomics: the 62.5-minute rule for Claude's cache
Steal the ideas, dodge the footguns, ship with confidence.
See you in the next issue!
FAUN.dev() Team
⭐ Patrons
faun.dev
Most engineers can run helm install. Far fewer can explain why their upgrade half-applied at 3 AM.
A practical course on what Helm actually does: state, releases, rendering, hooks, dependencies, rollbacks, GitOps integration, and the failure modes nobody writes blog posts about.
For engineers tired of treating Helm like a black box.
[Start the course →]
A practical course on what Helm actually does: state, releases, rendering, hooks, dependencies, rollbacks, GitOps integration, and the failure modes nobody writes blog posts about.
For engineers tired of treating Helm like a black box.
[Start the course →]

eventbrite.co.uk
Are Your APIs Ready for AI Agents? A Hands-on Workshop on May 23rd
AI agents are beginning to autonomously call APIs, chain services, and create integrations that most platforms were never designed to handle. This hands-on masterclass on Designing AI-ready APIs helps architects and developers build governed, predictable API ecosystems using OpenAPI, Overlay, and Arazzo.
Learn how to add guardrails, improve discoverability, and safely evolve existing APIs for automated consumption.
FAUN.dev readers get an exclusive 40% discount using code FAUN40.
AI agents are beginning to autonomously call APIs, chain services, and create integrations that most platforms were never designed to handle. This hands-on masterclass on Designing AI-ready APIs helps architects and developers build governed, predictable API ecosystems using OpenAPI, Overlay, and Arazzo.
Learn how to add guardrails, improve discoverability, and safely evolve existing APIs for automated consumption.
FAUN.dev readers get an exclusive 40% discount using code FAUN40.
🔗 Stories, Tutorials & Articles
docker.com
Docker made Custom Catalogs and Profiles available for MCP servers. Admins can distribute server catalogs they approve, and teams can package per-developer configurations as OCI artifacts.
claude.com
Anthropic breaks down the patterns behind successful Claude Code rollouts in monorepos, legacy systems, and codebases spanning thousands of developers, arguing that Claude Code performs agentic search over a live filesystem instead of relying on a RAG index that drifts out of sync with active engineering teams.
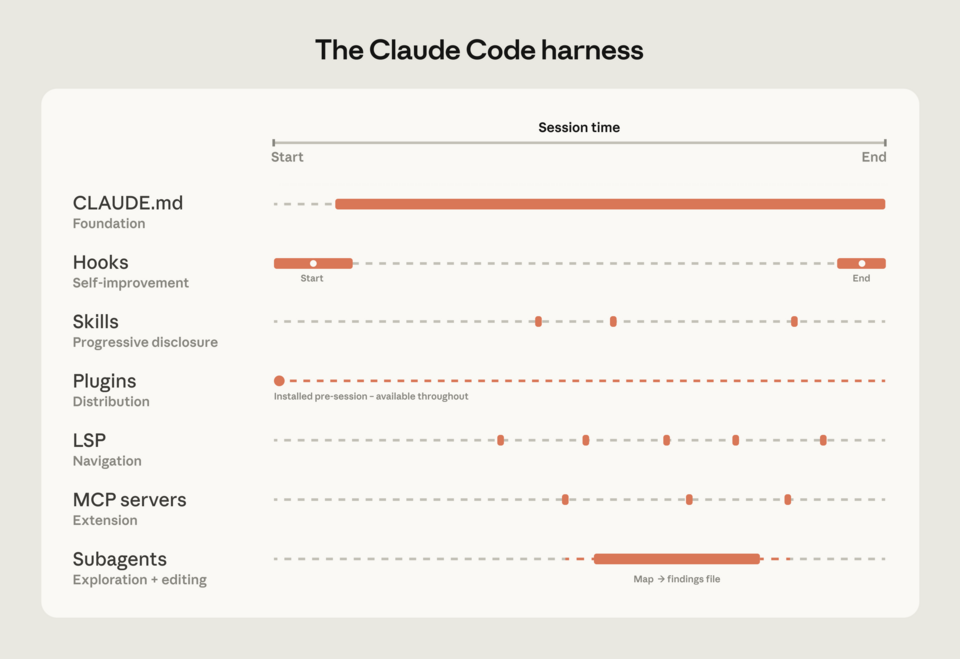
How you configure Claude matters more than the model itself. CLAUDE.md files, hooks, skills, plugins, MCP servers, LSP integrations, and subagents all load context in different ways. Teams that combine them with intent, instead of dumping everything into CLAUDE.md, navigate large codebases much better.
How you configure Claude matters more than the model itself. CLAUDE.md files, hooks, skills, plugins, MCP servers, LSP integrations, and subagents all load context in different ways. Teams that combine them with intent, instead of dumping everything into CLAUDE.md, navigate large codebases much better.
venturebeat.com
New data shows Microsoft and OpenAI leading agent orchestration, but Anthropic's rising stake signals a shift in control of AI infrastructure. Anthropic's move from model to orchestration layer hints at a strategic battle over agent runtime platforms where operational AI work happens.
brijeshdeb.medium.com
Brijesh Deb's third "comfortable lie" of software testing is that AI is now doing the testing: coverage dashboards hit 80%+, regression suites maintain themselves, and leadership concludes that risk is handled, while the experienced testers who knew the domain quietly get redeployed or made redundant.
His core distinction is that AI predicts from what already exists (code, docs, historical tests) but cannot exercise testing judgement, which lives in the gap between what is documented and what real users actually do, including the undocumented business rules nobody thought to write down.
He illustrates this with a fintech case where AI-generated tests covered every documented requirement perfectly, then a regional payment failure surfaced from a sequencing rule held only as tacit knowledge by two ops people, and argues AI works well only as an amplifier of human judgement, not a replacement for the person whose job is to ask whether the green dashboard is covering the right things.
His core distinction is that AI predicts from what already exists (code, docs, historical tests) but cannot exercise testing judgement, which lives in the gap between what is documented and what real users actually do, including the undocumented business rules nobody thought to write down.
He illustrates this with a fintech case where AI-generated tests covered every documented requirement perfectly, then a regional payment failure surfaced from a sequencing rule held only as tacit knowledge by two ops people, and argues AI works well only as an amplifier of human judgement, not a replacement for the person whose job is to ask whether the green dashboard is covering the right things.
skids.dev
Ryan Skidmore works out the tokenomics of Anthropic's prompt cache and lands on a single rule: if you expect to need a cached prefix again within 62.5 minutes, keep refreshing it with cheap reads; past that, let it expire and rewrite, because a 5-minute cache write costs 1.25x base input and a read costs 0.10x, so the ratio collapses to 5 * (1.25 / 0.10) regardless of model or prefix size.
He flags three cache footguns that silently torch the math: Opus 4.7 uses a new tokenizer that can balloon the same text by 35%, prefixes under the model's minimum (4,096 tokens for Opus, 1,024 for Sonnet) don't cache at all and fail silently, and the cache breakpoint only looks back 20 content blocks, so long agent transcripts need an earlier breakpoint to stay hit.
He extends the same model-independent math to /compact, where break-even depends only on the compression ratio: roughly 10:1 pays back in 8 turns, 5:1 in 17, and anything closer to 2:1 is just an expensive summary that also risks dropping the error message your agent will have to rediscover.
He flags three cache footguns that silently torch the math: Opus 4.7 uses a new tokenizer that can balloon the same text by 35%, prefixes under the model's minimum (4,096 tokens for Opus, 1,024 for Sonnet) don't cache at all and fail silently, and the cache breakpoint only looks back 20 content blocks, so long agent transcripts need an earlier breakpoint to stay hit.
He extends the same model-independent math to /compact, where break-even depends only on the compression ratio: roughly 10:1 pays back in 8 turns, 5:1 in 17, and anything closer to 2:1 is just an expensive summary that also risks dropping the error message your agent will have to rediscover.
⭐ Supporters
eventbrite.co.uk
Modern platform teams are under pressure to scale cloud-native systems faster while improving reliability, security, developer experience, and operational efficiency. AI is changing how platforms are designed and operated — from intelligent automation and observability to AI-native developer platforms and autonomous operations.
Join leading experts from WSO2, CNCF, cloud-native, and DevSecOps communities for a practical workshop focused on building scalable, secure, and intelligent AI-native platforms.
Register Here: Building AI-Native Platform Engineering Systems Tickets, Saturday, May 30 • 7 PM - 11:59 PM GMT+5 | Eventbrite
Join leading experts from WSO2, CNCF, cloud-native, and DevSecOps communities for a practical workshop focused on building scalable, secure, and intelligent AI-native platforms.
Register Here: Building AI-Native Platform Engineering Systems Tickets, Saturday, May 30 • 7 PM - 11:59 PM GMT+5 | Eventbrite

⚙️ Tools, Apps & Software
github.com
Automatically completes the full workflow from requirement research → research review → planning → plan review → development → development review using → test AI large language models. Capable of autonomously handling medium to large-scale engineering projects.
github.com
AI-guided self-hosting for 950+ open-source apps on any cloud. Works with Claude Code, Codex, Cursor, Aider, OpenClaw, Hermes — catalog self-improves from user feedback.
github.com
AI gateway written in Go. Lightweight unified OpenAI-compatible API for OpenAI, Anthropic, Gemini, Groq, xAI & Ollama. LiteLLM alternative with observability, guardrails, streaming, costs and usage tracking.
github.com
Your Personal AI super intelligence. Private, Simple and extremely powerful.
🤔 Did you know?
Did you know that TFRA, TensorFlow's recommender extension, has an embedding layer that grows as new IDs appear instead of demanding the full vocabulary up front? Regular embedding layers need a fixed size at creation, which falls apart when your users and items are constantly changing. TFRA stores embeddings in a hash table that expands on demand and can drop IDs that stop showing up, which is how production recommenders handle billion-scale catalogs without running out of memory.
🤖 Once, SenseiOne Said
"The hardest part of deploying ML is admitting the model is the easy part; everything else is a system that quietly changes the question while you keep measuring the answer. MLOps exists because prediction is cheap and accountability is expensive."
SenseiOne
SenseiOne
😂 Meme of the week
