| |
| 🔗 Stories, Tutorials & Articles |
| |
|
| |
| Cisco Bets On WideField Security Acquisition To Tackle Agentic AI Security Gap |
| |
| |
| Cisco executives plan to acquire WideField Security so Cisco teams can add identity and session telemetry to agentic AI security operations. |
|
| |
|
| |
|
| |
| Model Size Scaling in 2023-2031 |
| |
| |
| Token generation speed is constrained by the speed at which the relevant HBM can be read, depending on model size and pipeline setup. Model sizes feasible for each year between 2023 and 2031 range from 10T in 2026 to 1.4 quadrillion in 2031, with pretraining compute and HBM specifications playing essential roles. Constraints on total params and active params from pretraining compute are key factors in determining model feasibility for each year. |
|
| |
|
| |
|
| |
| AI's Affordability Crisis |
| |
| |
| The AI platforms are running the drug-dealer's algorithm, with subsidies resulting in overwhelming demand for their products. Estimates show that the cost of generating tokens ranges from $8 to $14 to generate $1 in revenue. Companies transitioning to token-based pricing have seen significant increases in costs, prompting considerations of price cuts and adjustments. |
|
| |
|
| |
|
| |
| Everything a Senior Engineer Needs to Know About What's Inside an LLM |
| |
| |
| As an engineer, understanding AI internals can be challenging. Part Two of this series covers the hardware behind AI, including transistors and semiconductors, and model architecture. Transforming the concept of self-attention, the transformer architecture has become a crucial development in neural networks, paving the way for models like GPT and BERT. |
|
| |
|
|
| |
|
| |
| GLM-5.2 vs Claude Opus |
| |
| |
| After a head-to-head coding test, you can use GLM-5.2 as a low-cost open-weights coding model and choose Opus when you need stronger correctness, faster responses, or visual self-checking. |
|
| |
|
| |
|
| |
| The Problem is Prompt Debt |
| |
| |
| Teams create prompt debt when they hand-tune prompts. They turn natural-language instructions into fragile specs, spend more time adjusting wording, and tie the application to one model. |
|
| |
|
| |
|
| |
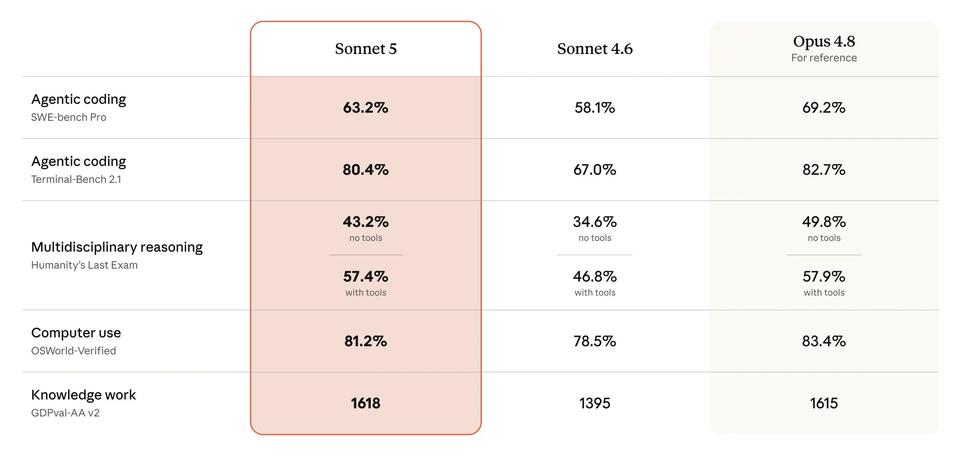
| Introducing Claude Sonnet 5 |
| |
| |
| Anthropic launched Claude Sonnet 5, its most agentic Sonnet model, and set it as the default for Free and Pro users. |
|
| |
|
|
| |
👉 Got something to share? Create your FAUN Page and start publishing your blog posts, tools, and updates. Grow your audience, and get discovered by the developer community. |