| |
| 🔗 Stories, Tutorials & Articles |
| |
|
| |
| Best Practices for Kubernetes Readiness and Liveness Probes ✅ |
| |
| |
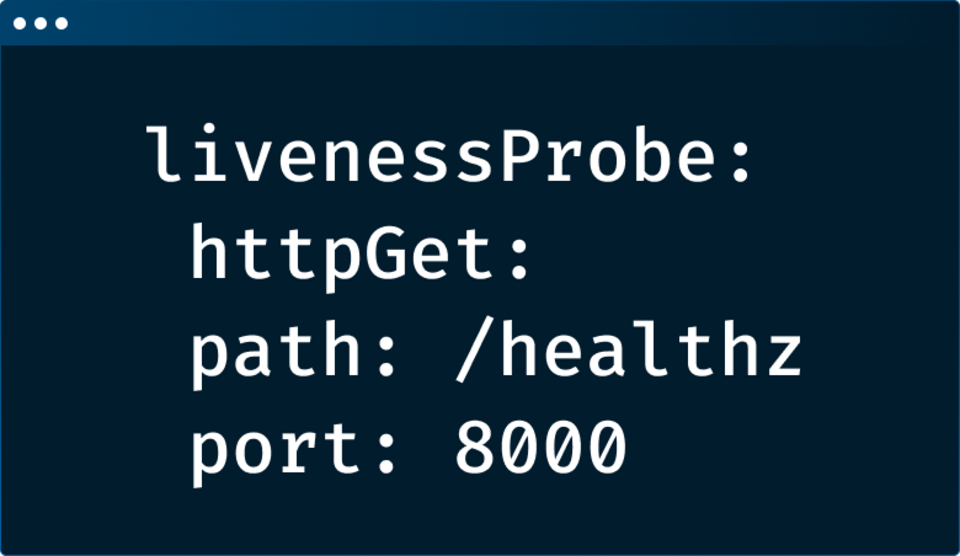
The biggest mistake Kubernetes admins make with health probes isconfiguring the probes the same way for all apps.
The article provides six best practices for configuring liveness and readiness probes based on the app's startup time, response time, criticality, and issues. Additionally, the article suggests checking the entire application to determine its real state rather than setting up a high-level HTTP check. |
|
| |
|
|
| |
|
| |
| Top 10 Microservices Design Patterns and Principles - Examples |
| |
| |
This article discusses essential Microservice design principles and patterns for experienced developers. It explains the benefits of Microservice architecture over monolithic architecture, and covers concepts such as scalability, flexibility, resiliency, and event sourcing.
The article also discusses ten main design patterns including BFF, API Gateway, Saga, and CQRS. Finally, it provides examples of how to handle partial failures and why an API Gateway is necessary for large applications with multiple client apps. |
|
| |
|
| |
|
| |
| Degenerate Leadership Principles ✅ |
| |
| |
The Amazon Leadership Principles (LPs) can be weaponized or applied in a degenerate, simplistic way.
However, as imperfectly used, they provide a consistent internal language for the company. The Frugality LP is a common example of degenerate application, where saving money is prioritized over value.
When faced with oversimplification or laziness in applying a principle, it's best to encourage a more thorough, nuanced interpretation through exploring new possibilities or asking "what would need to be true...?"
All guidelines and principles are only useful if thoughtfully applied to specific circumstances. |
|
| |
|
| |
|
| |
| MTTR: lower isn’t always better ✅ |
| |
| |
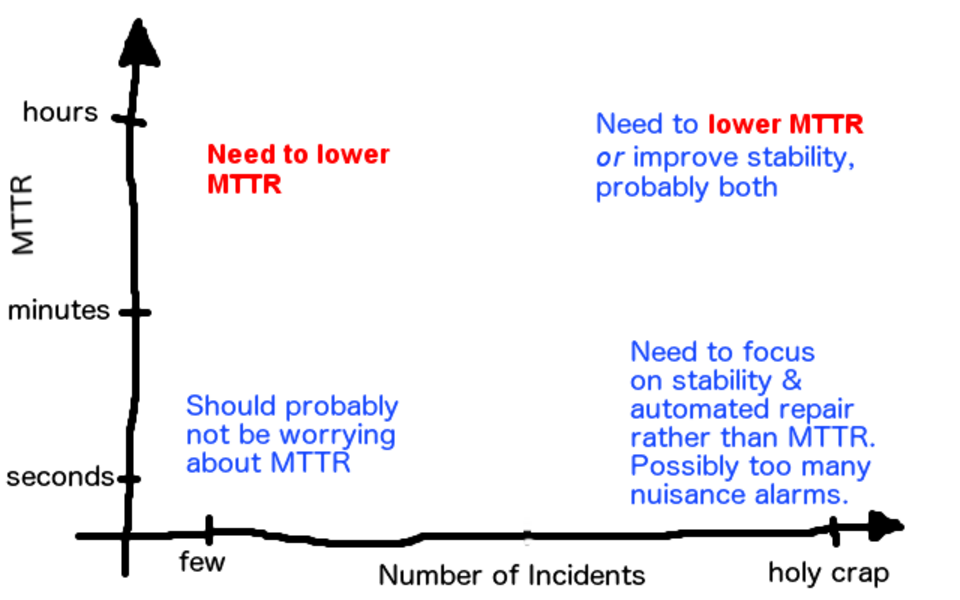
MTTR (Mean Time To Recover) is a useful operational metric to track, but it doesn't always tell the whole story. It's only an average and doesn't take into account the total amount of downtime.
Lowering MTTR may be a good strategy in certain situations, but it's not always the right strategy. The goal should be to minimize downtime and noise, not just MTTR. It's important to consider the whole picture and not be misled by intuition when making decisions. |
|
| |
|
|
| |
|
| |
| Don’t overcategorise incidents ✅ |
| |
| |
A discussion on the difference between "network incidents" and "security incidents" led to a realization that categorizing incidents may not be effective for complex situations like major incidents, such as ransomware.
Ransomware impacts multiple aspects of infrastructure and requires a significant, challenging response from multiple stakeholders.
Causal analysis is complex and requires attention to various aspects such as system architecture, email security, user training, etc.
Complex systems fail in complex ways, and categorization can become meaningless or adversely impact an organization's flexibility and capability to respond. |
|
| |
|
| |
👉 Got something to share? Create your FAUN Page and start publishing your blog posts, tools, and updates. Grow your audience, and get discovered by the developer community. |